Say Anything: Natural language prompting for Meta's Segment Anything Model
Suvansh Sanjeev • 2023-04-12
A Chrome extension adding natural language prompting functionality over Meta’s SAM demo
Try Say Anything here! The extension and backend server are both open source.
The recent launch of Meta's Segment Anything Model (SAM) has generated much excitement, particularly with its captivating demo. However, the absence of the anticipated natural language prompting component left many feeling disappointed. In this blog post, we'll take you through our experiment with SAM, the techniques we used to enhance its capabilities to include natural language prompting, and some fun results.
Approach
To integrate natural language prompting with the SAM demo, we needed to locate regions of the image that corresponded to the prompt. We achieved this by combining OpenAI's CLIP model, Gradient-weighted Class Activation Mapping (Grad-CAM), and a Laplacian of Gaussian (LoG) filter. Here's a step-by-step breakdown of our approach:
- We used the CLIP model to score text against images. CLIP, which stands for "Contrastive Language-Image Pretraining," is designed to understand images and text in a joint embedding space. By scoring text against images, CLIP helps us identify the relevance of an image to a prompt.
- With GradCAM, we generated heat maps from the gradients and activations of the CLIP model. GradCAM provides a visual explanation for the model's decisions, highlighting the regions in the image that contributed the most to the output. The result of this step is a heat map like the one in Figure 1. Kevin Zakka's implementation was helpful in our experimentation.
- After obtaining the heat maps, we use the Laplacian of Gaussian (LoG) filter to capture the most prominent blobs (regions of interest) in the images. The LoG filter is a two-step process involving the application of a Gaussian filter to the image followed by the Laplacian operator. We apply the LoG filter at successively larger standard deviations, resulting in a 3D array, in which local maxima correspond to prominent blobs. We use scikit-image’s implementation.
Instead of building a separate user interface and re-hosting the model, we opted for a Chrome extension to facilitate interaction with the demo site. Automating interactions proved to be a bit challenging, but the time invested in developing the extension was worth it.

Figure 1: An example heat map resulting from Grad-CAM on the CLIP model with the text prompt “hands.”
Results
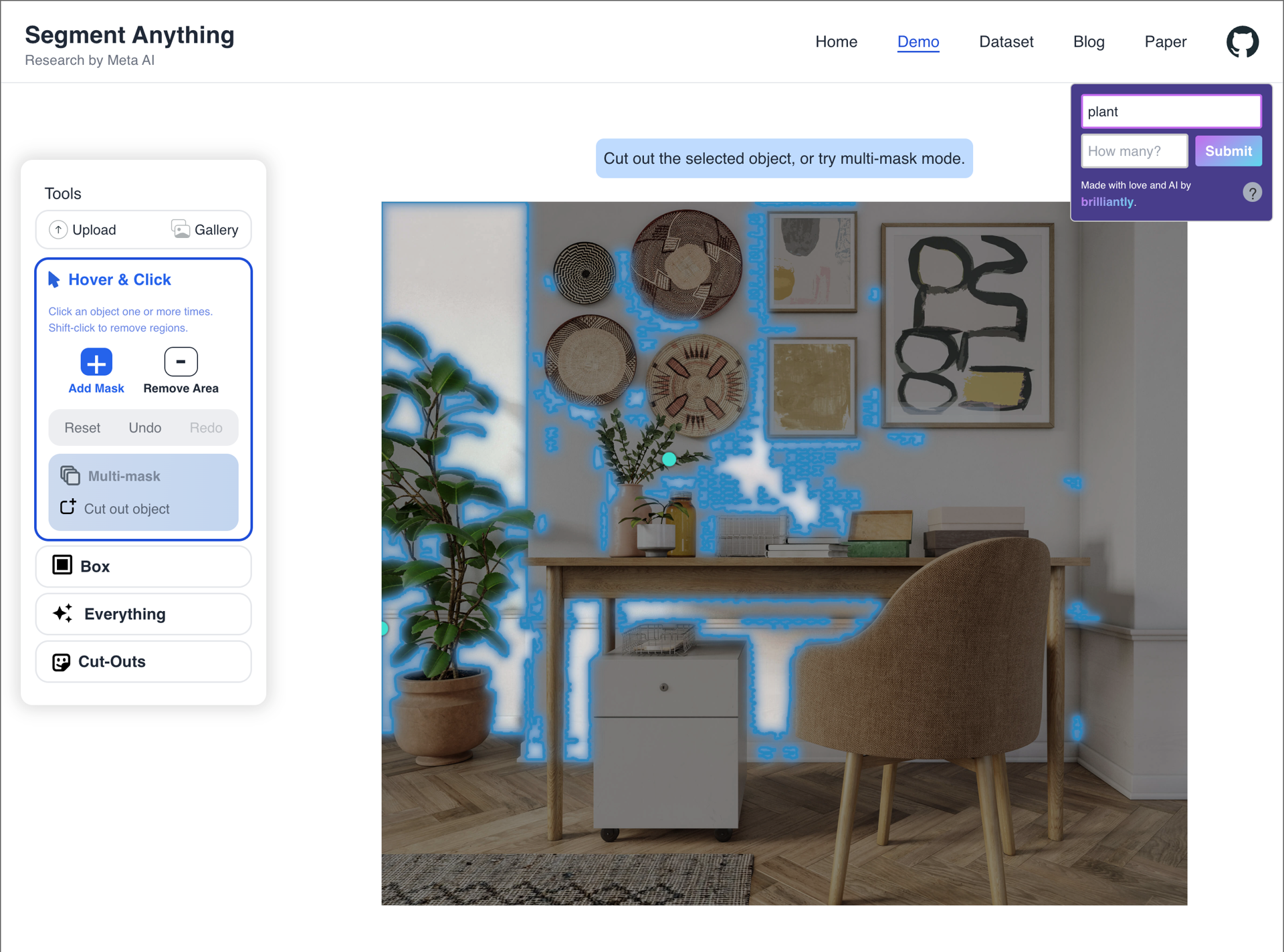
While testing this approach, we noticed four categories of results. For those unfamiliar with SAM, teal dots represent additive masks, while red dots (shown in videos, but not in photos) represent subtractive masks.
Near misses
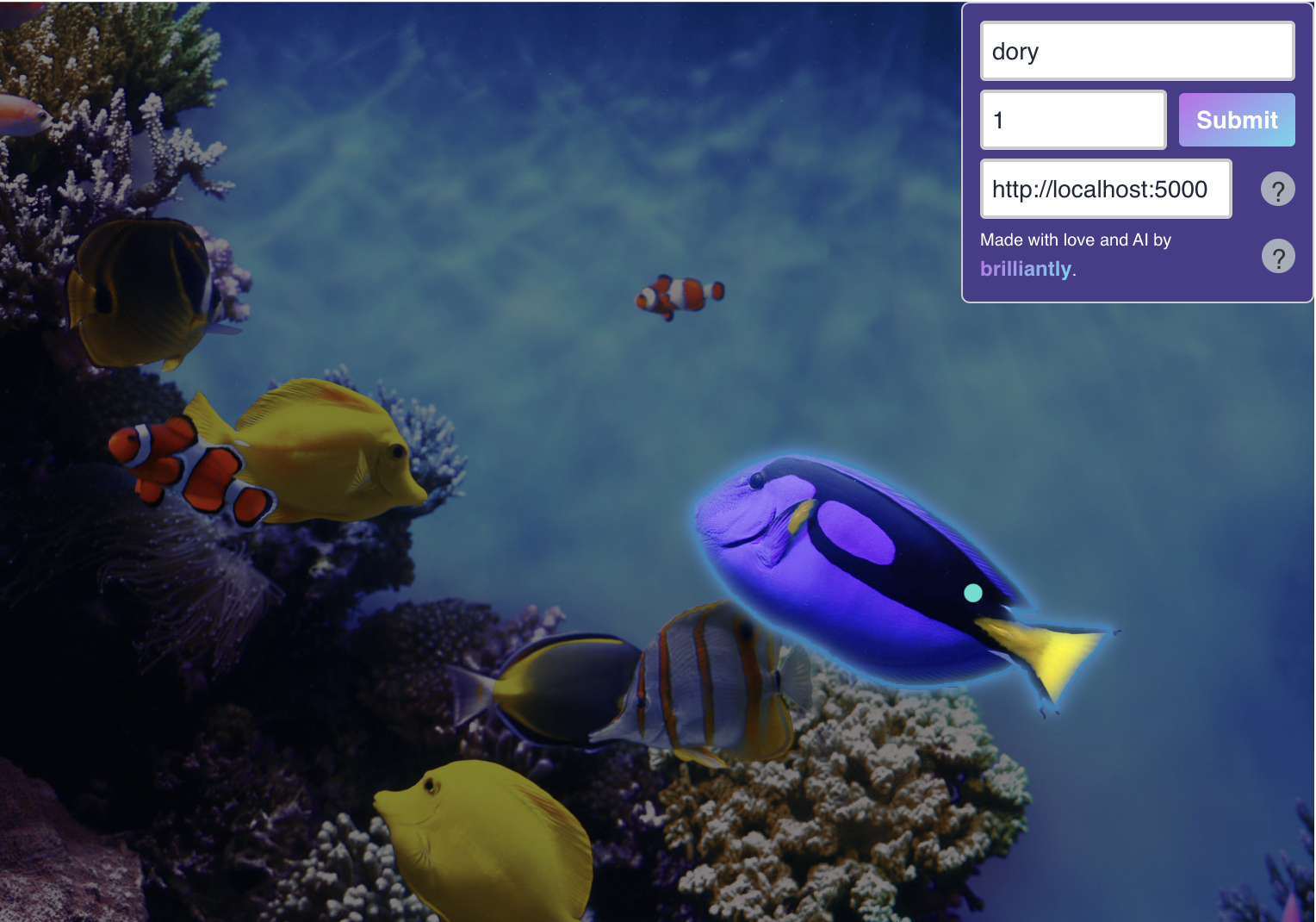
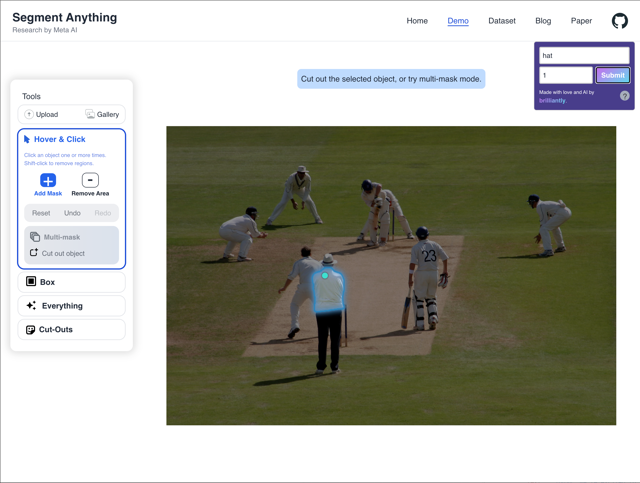
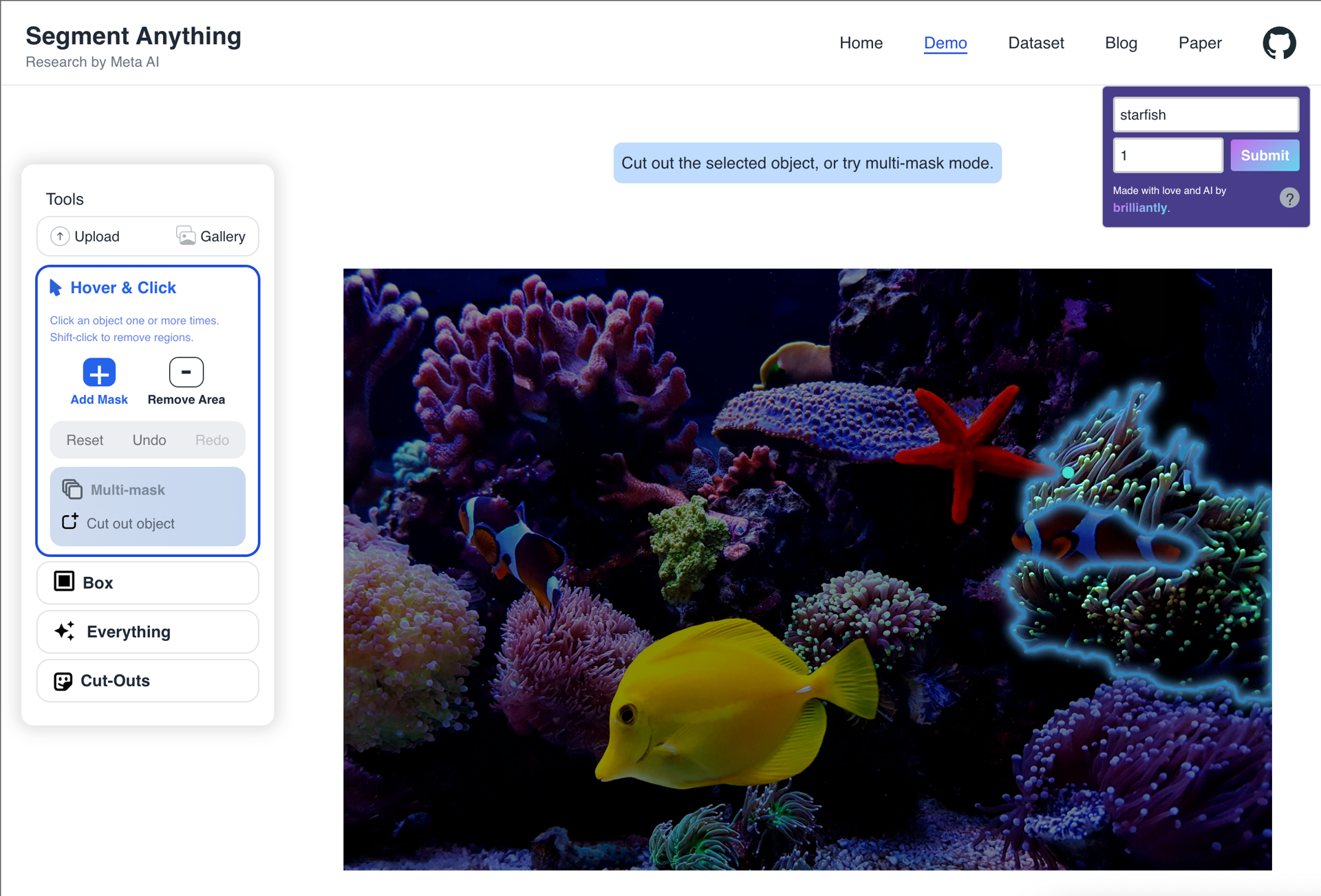
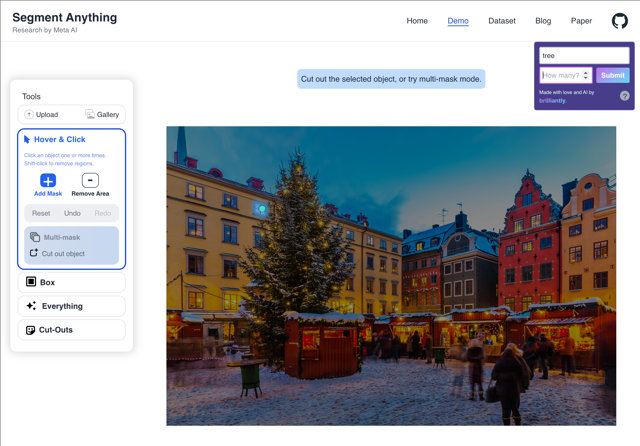
The model is close to achieving the desired output, but it selects a slightly different mask. This could be partly due to our choice of a "fat-fingered" approach with coarse blob selection over a heat map as described above. The prompts: "hat" (1), "starfish" (1), "tree", "stick".
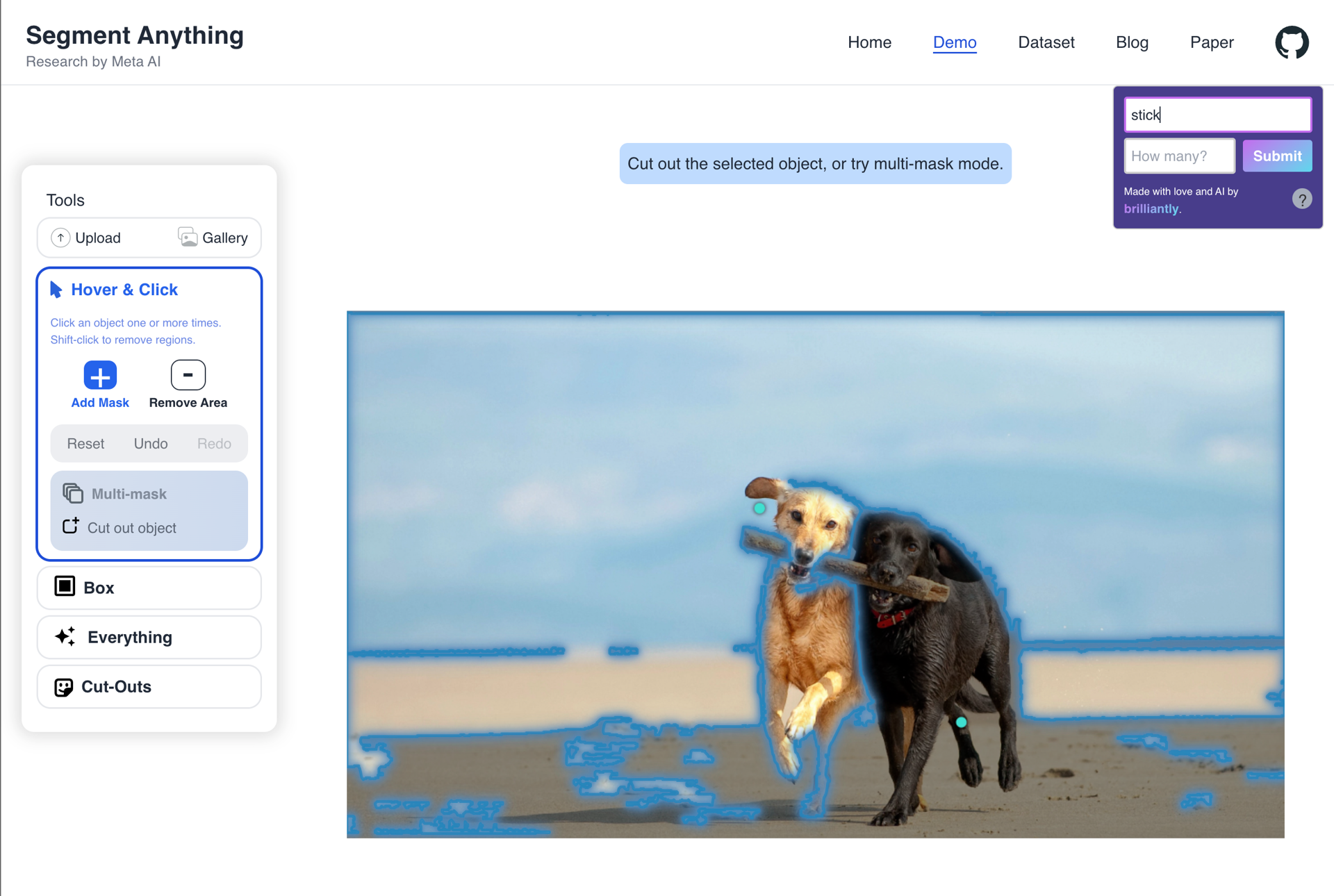
Good results
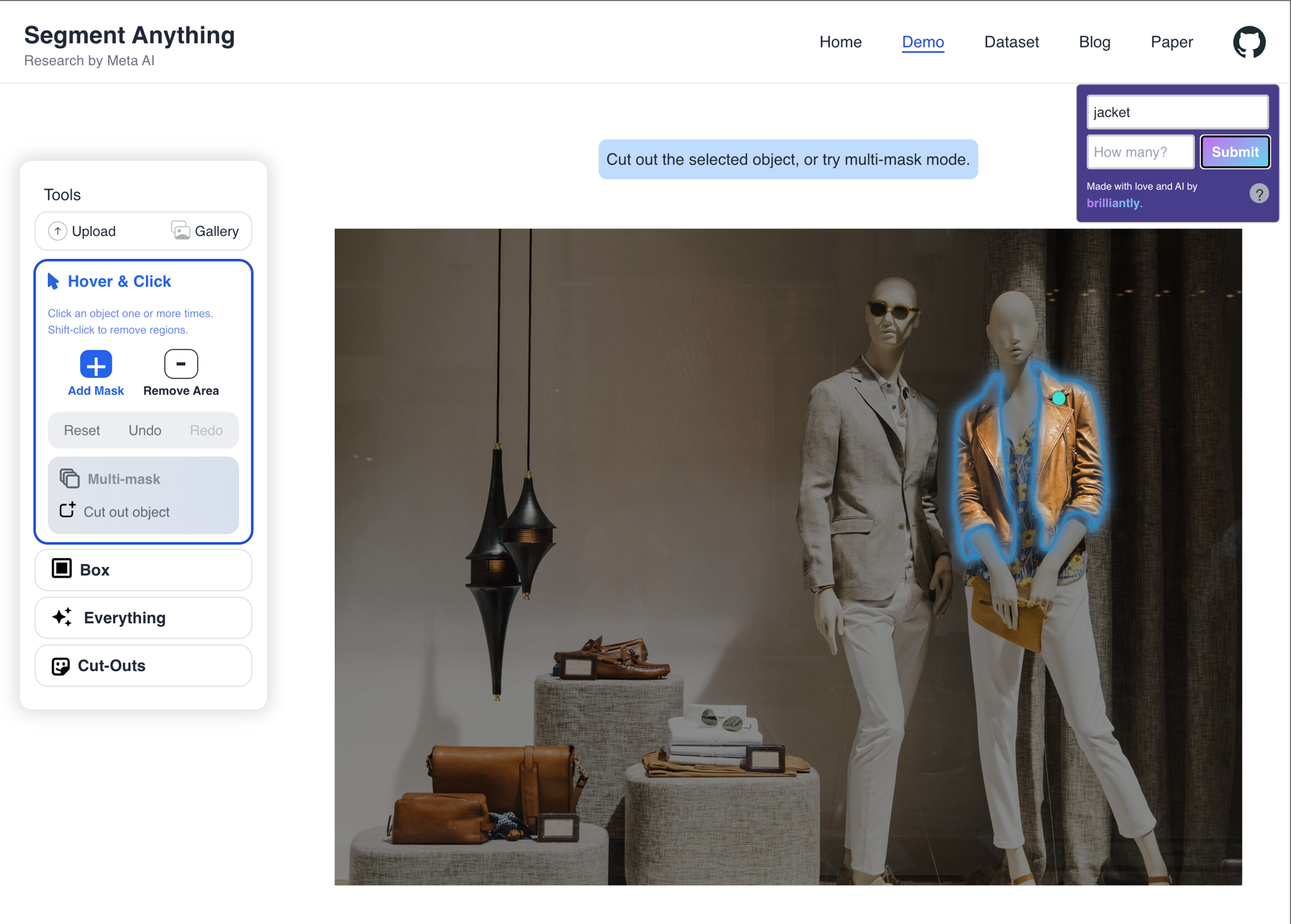
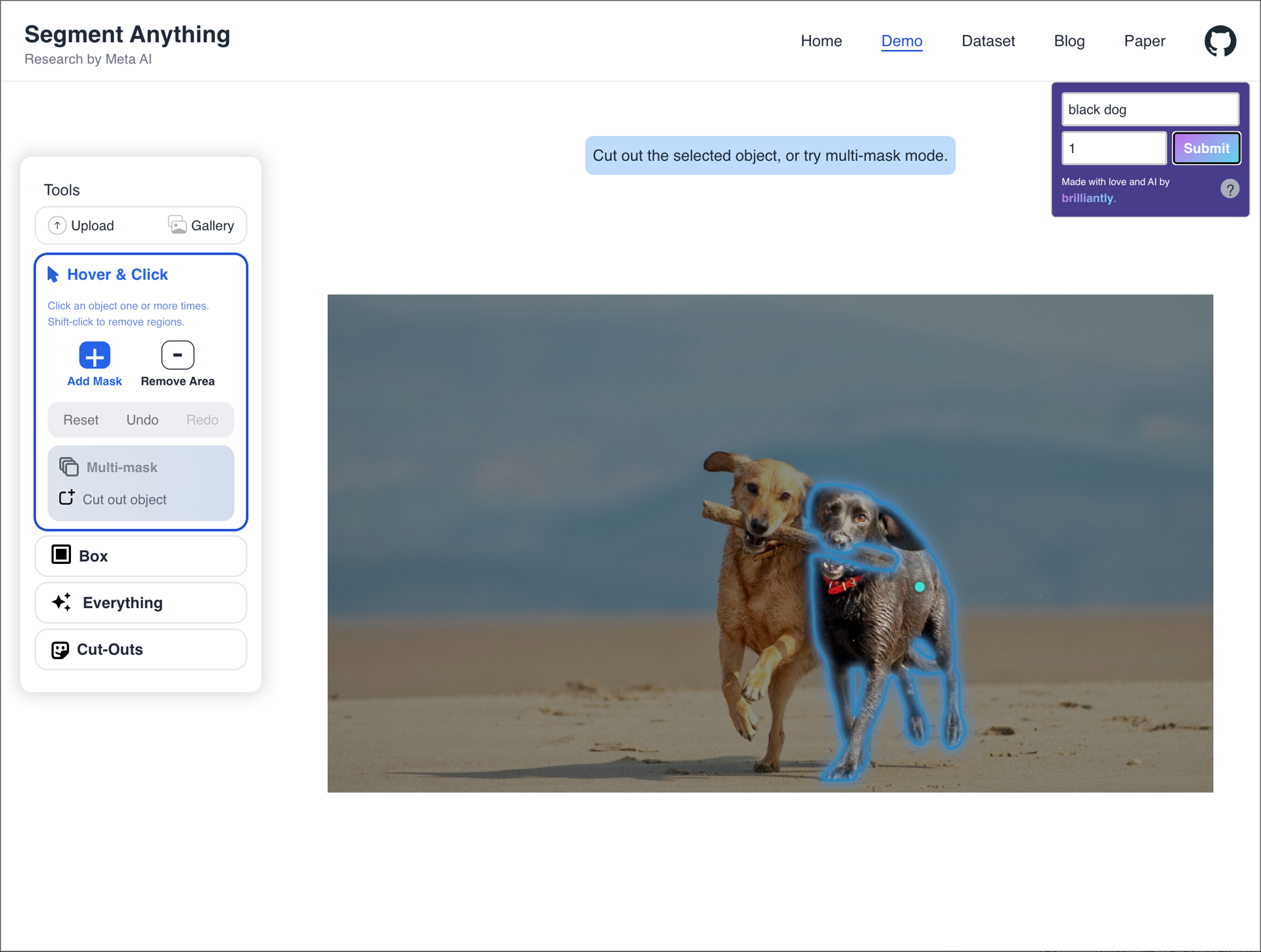
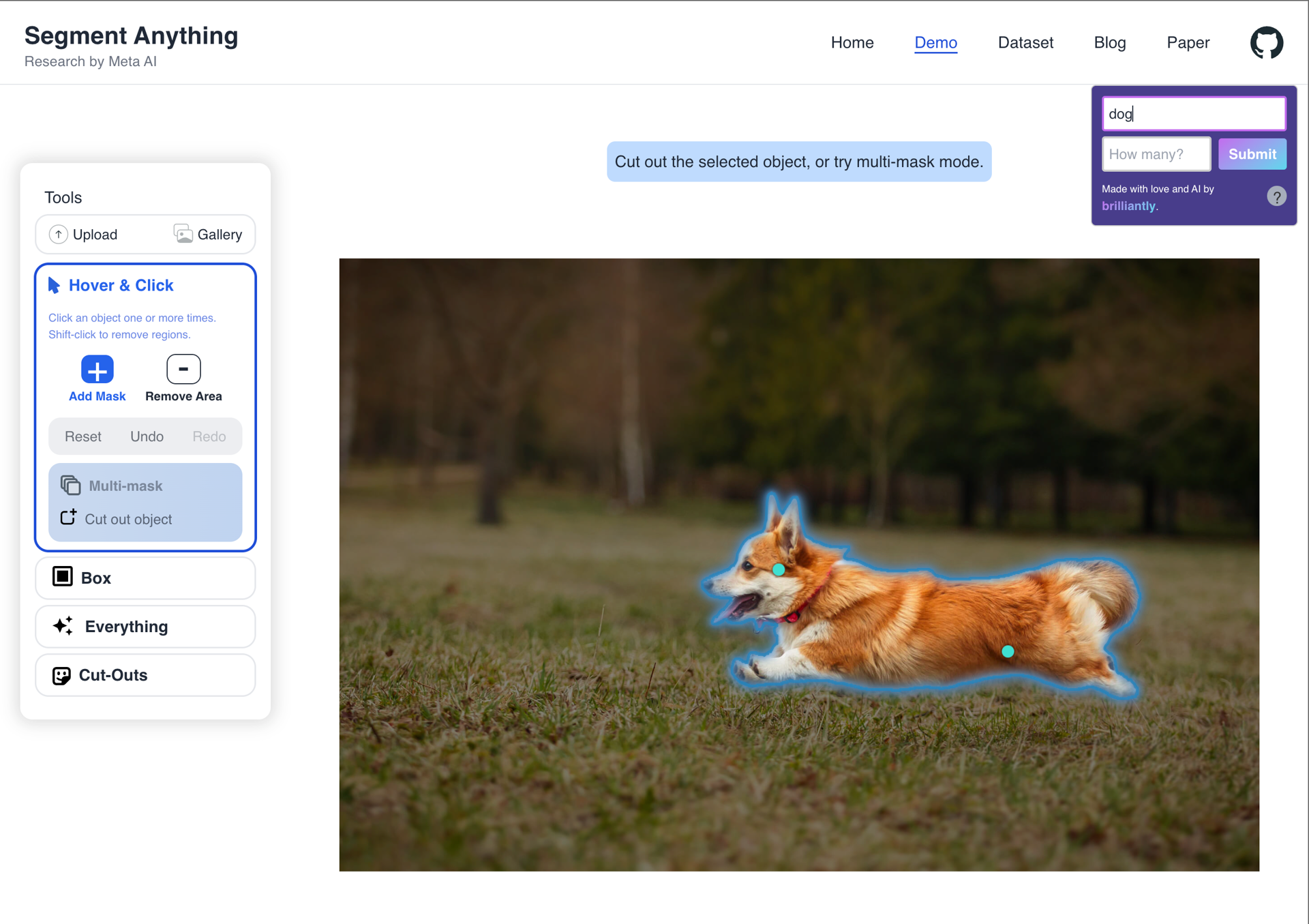
The model produces satisfactory results in many obvious cases. The prompts: "jacket", "black dog" (1), "dog", "plant".
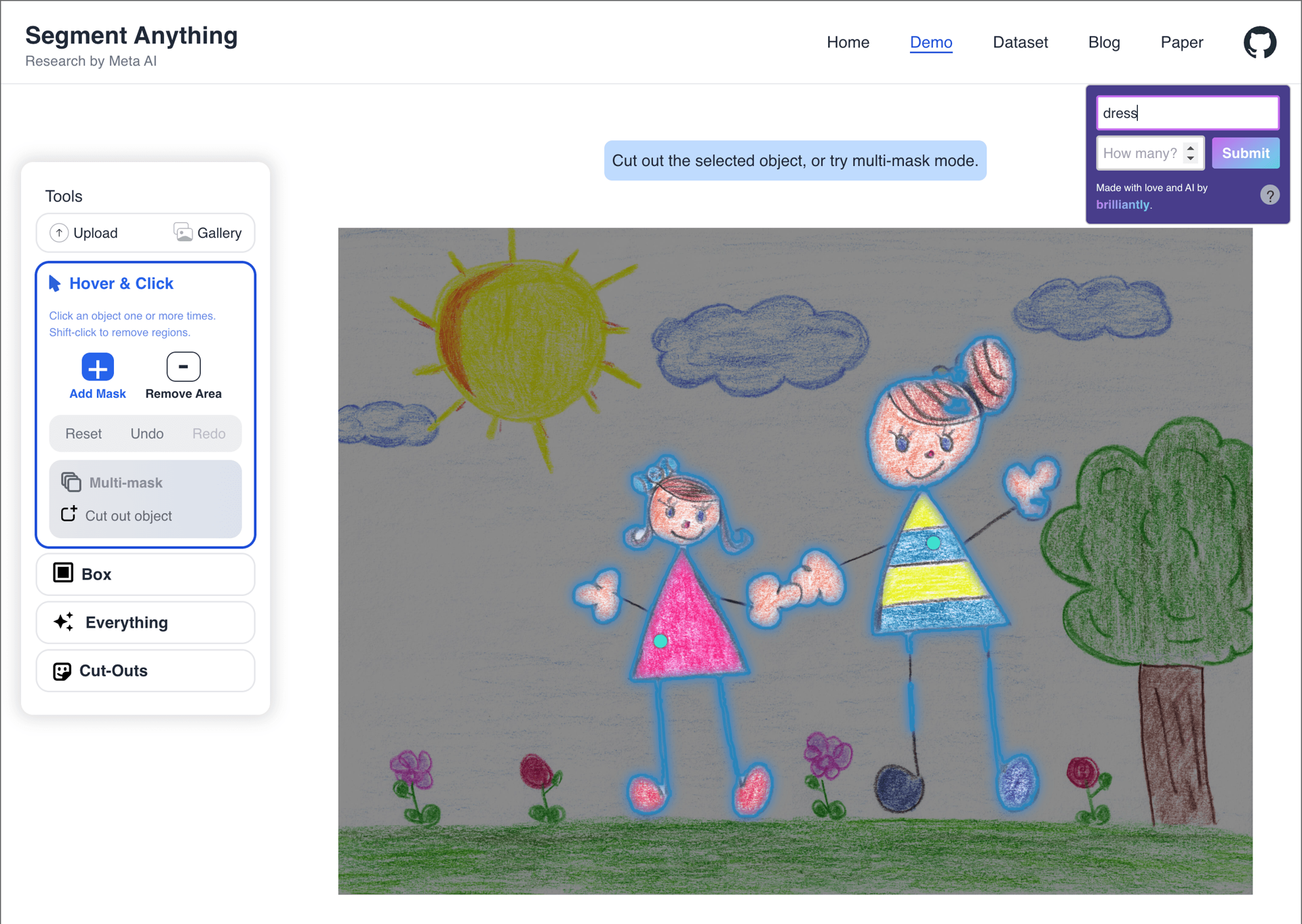
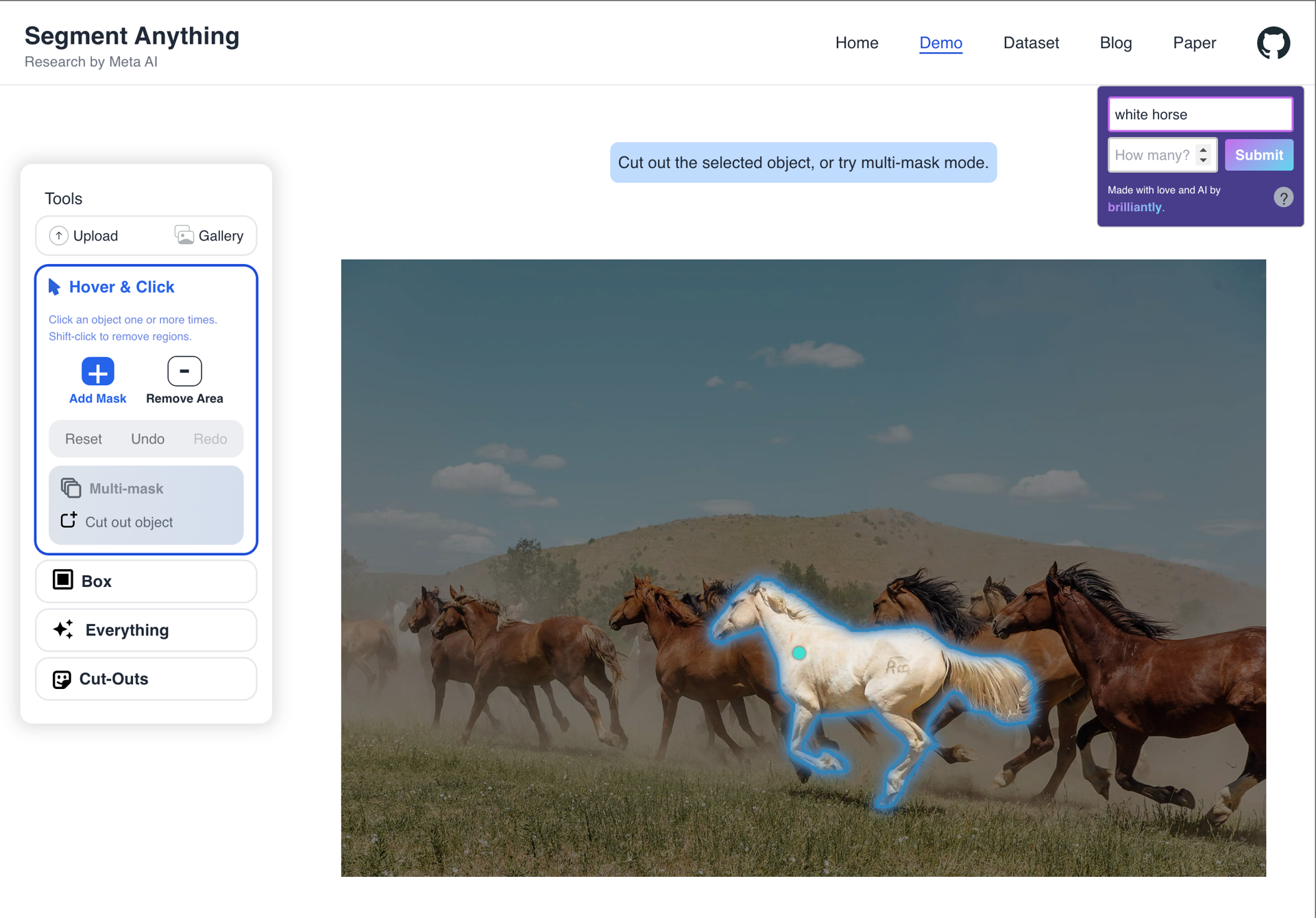
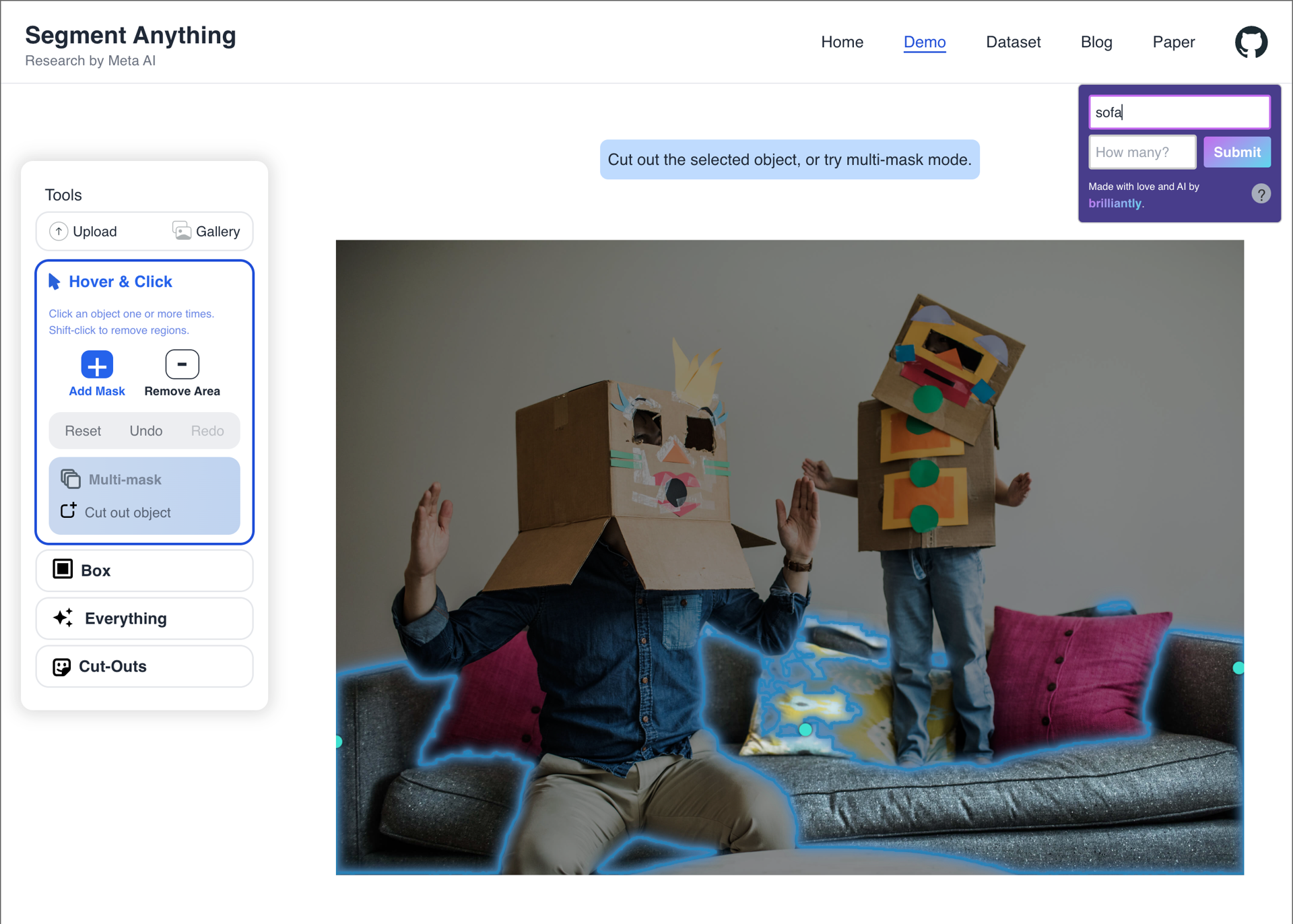
Surprising successes
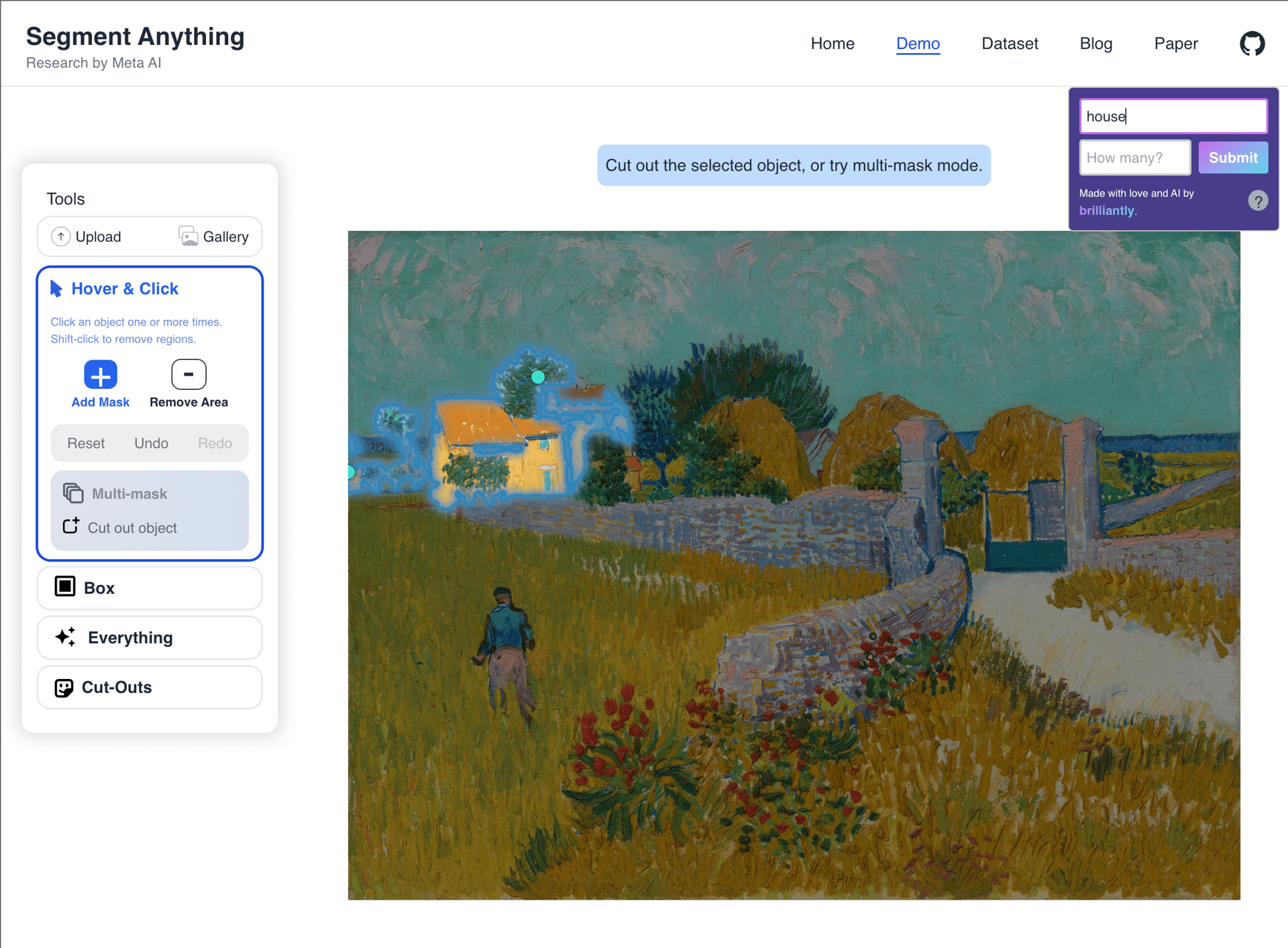
These are the most exciting results that caught us off guard, as we didn't expect the model to succeed given the background noise, distractions, or underspecified descriptions. The prompts: "dress", "white horse", "sofa", "house".
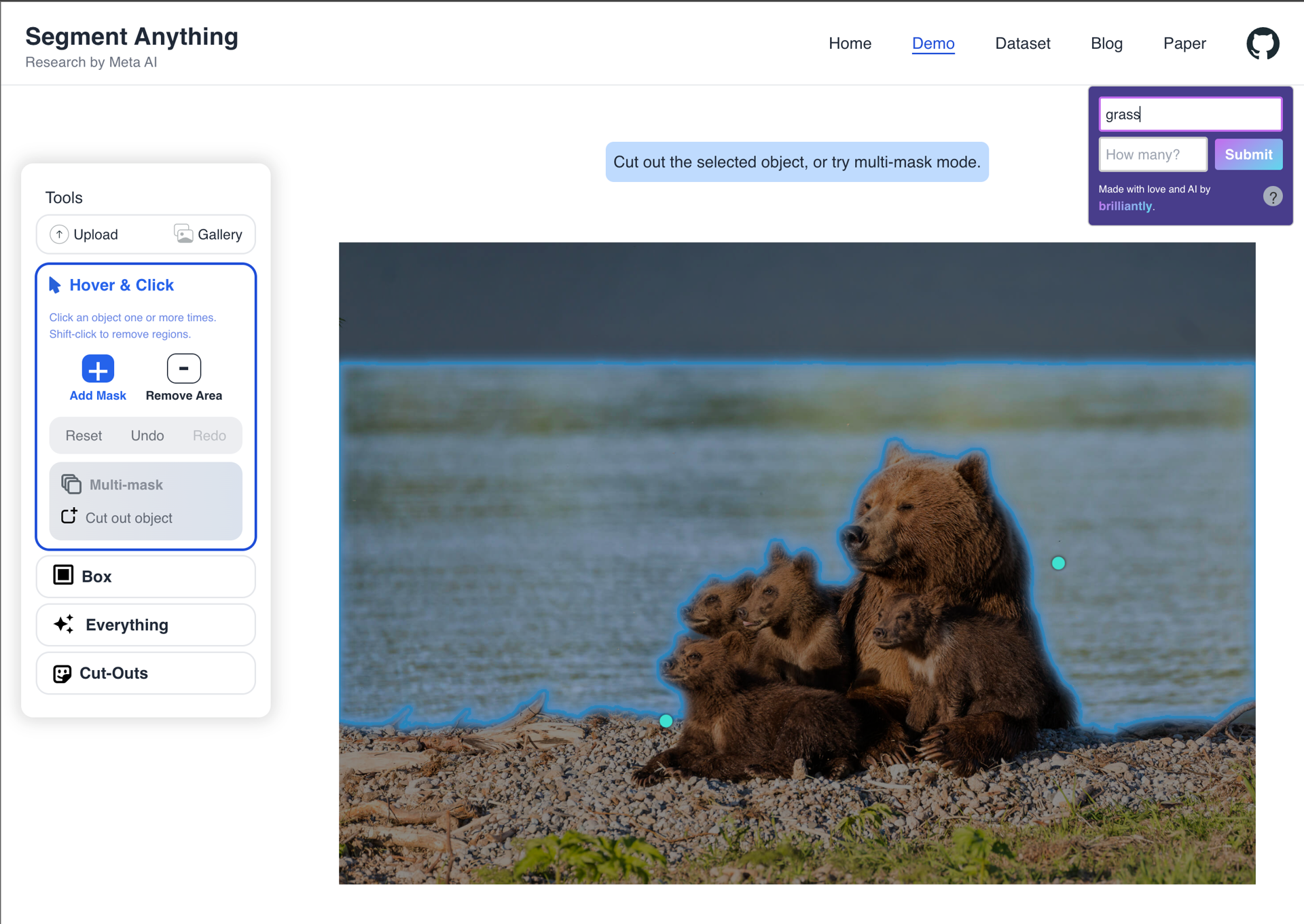
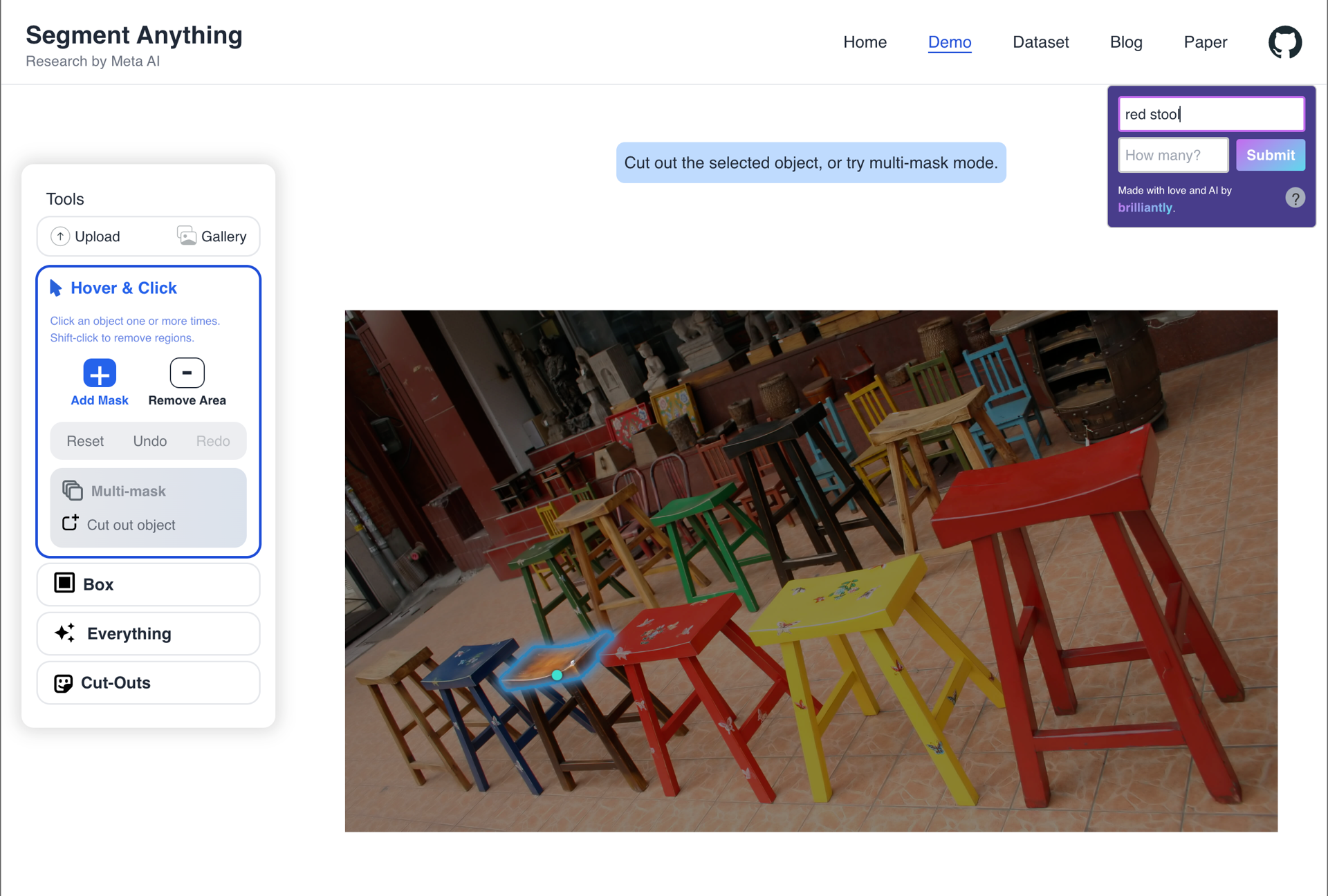
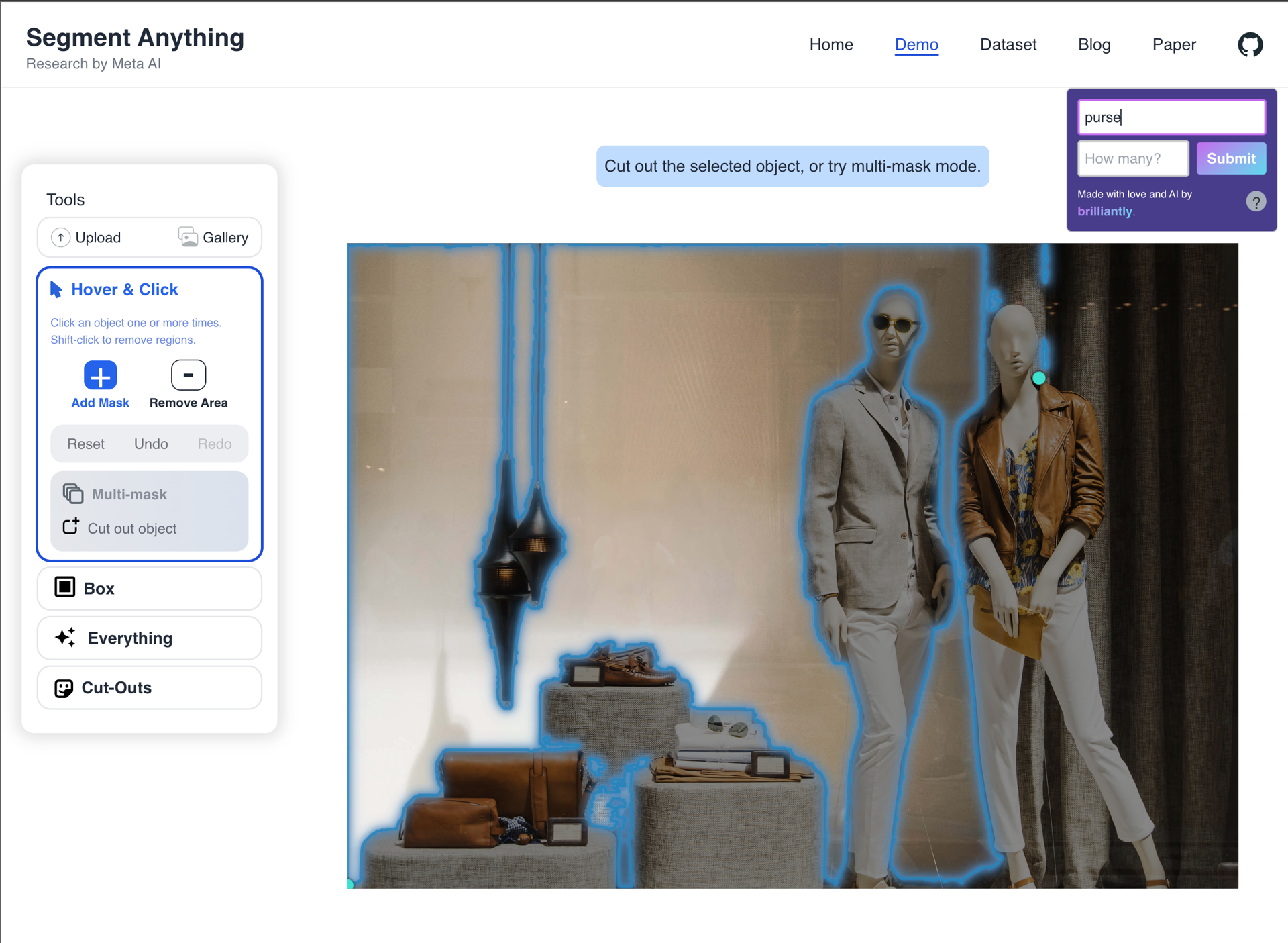
"Huh?" category
This category consists of unexpected or confusing behavior, which initially, we thought would comprise the majority of our queries. However, only roughly 30% of our results fell into this category. The prompts: "grass", "red stool", "purse", "rug".
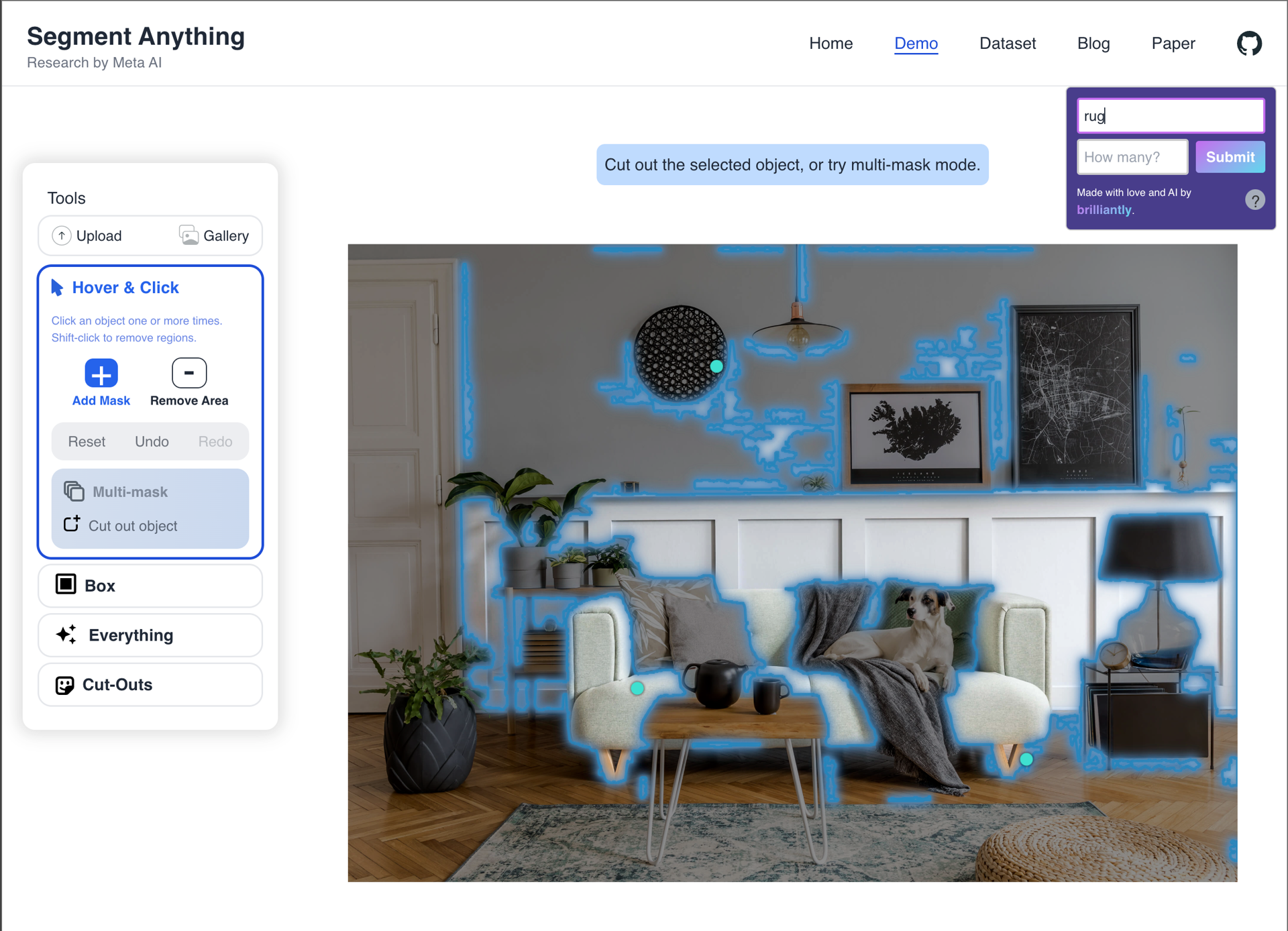
We also experimented with both additive and subtractive prompts, which can be seen in the demo videos. This approach allowed us to “Undo" extraneous clicks and change the number of prompts used, as they are performed in descending order of strength.
Figure 2: A video demonstration of additive and subtractive natural language prompting. The prompt "frog" selects all of the animals, so we switch to subtraction mode and use "turtle" and "snail" to remove the excess.
Figure 3: Another demonstration of additive and subtractive natural language prompting in order to select first the bridge, and then the skyline.
Improvements
While there's plenty of room for improvement, one alternative approach we considered was to gather all the patches provided by SAM, score them using CLIP, and apply a threshold. Although our initial implementation of this approach was slow and noisy, a weighting heuristic (like inverse area) could enhance the quality of this approach. However, we chose to prioritize speed and focused on sampling broadly within blobs to refine our results.
Getting Started
Install the Say Anything Chrome extension to get started here! It is also possible to run the backend server locally for a private solution. If you want to go this route, simply run the server according to the instructions in the README and point Say Anything to your server location by checking the "Use custom server" box.
Summary
Exploring Meta's Segment Anything Model and combining it with other techniques like CLIP, GradCAM, and Laplacian of Gaussian filters has shown promising results. While there are still improvements to be made, this exploration provides a glimpse into the potential of natural language prompting in image segmentation tasks. So, go ahead and give it a try, and feel free to send us feedback (or just say hi) at [email protected].
See More Posts

brilliantly Blog
Stay connected and hear about what we're up to!